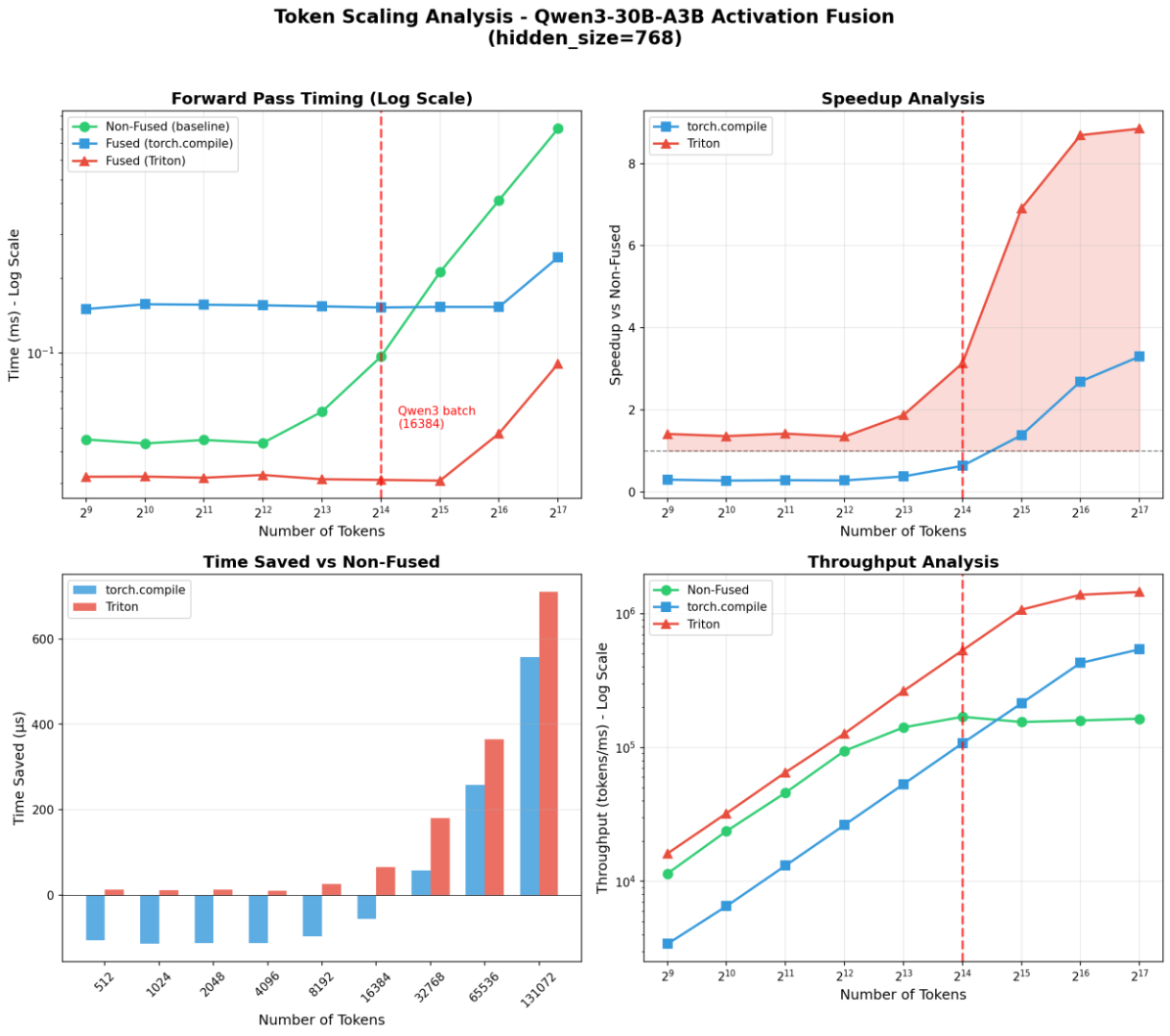
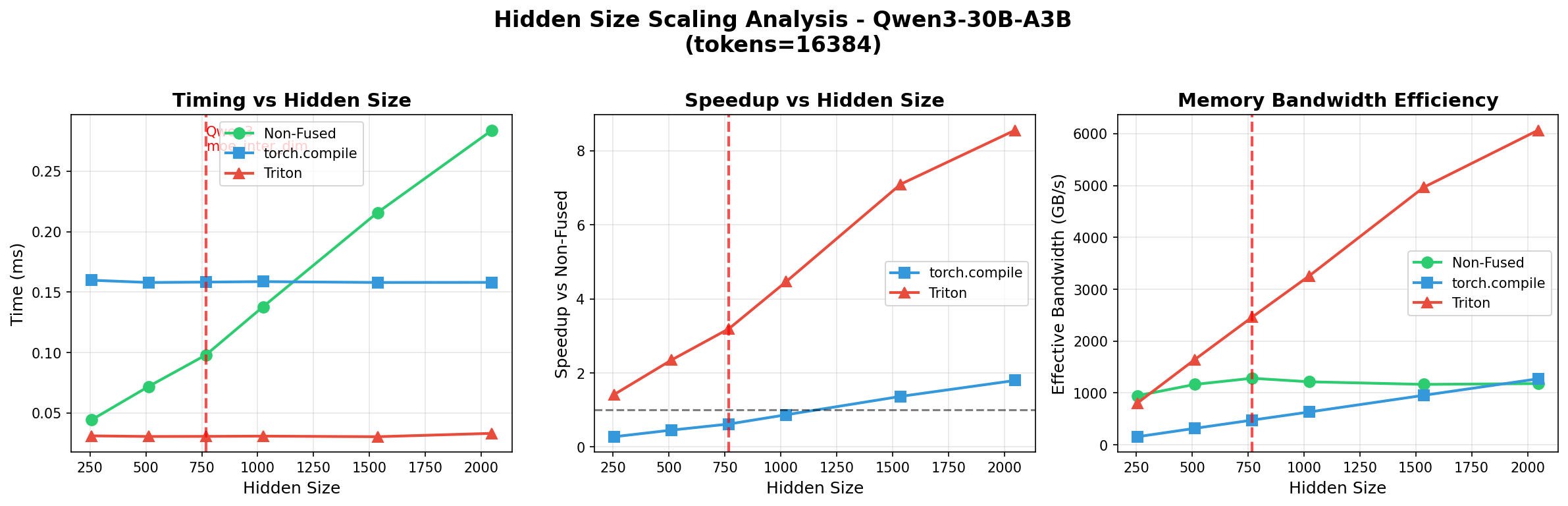
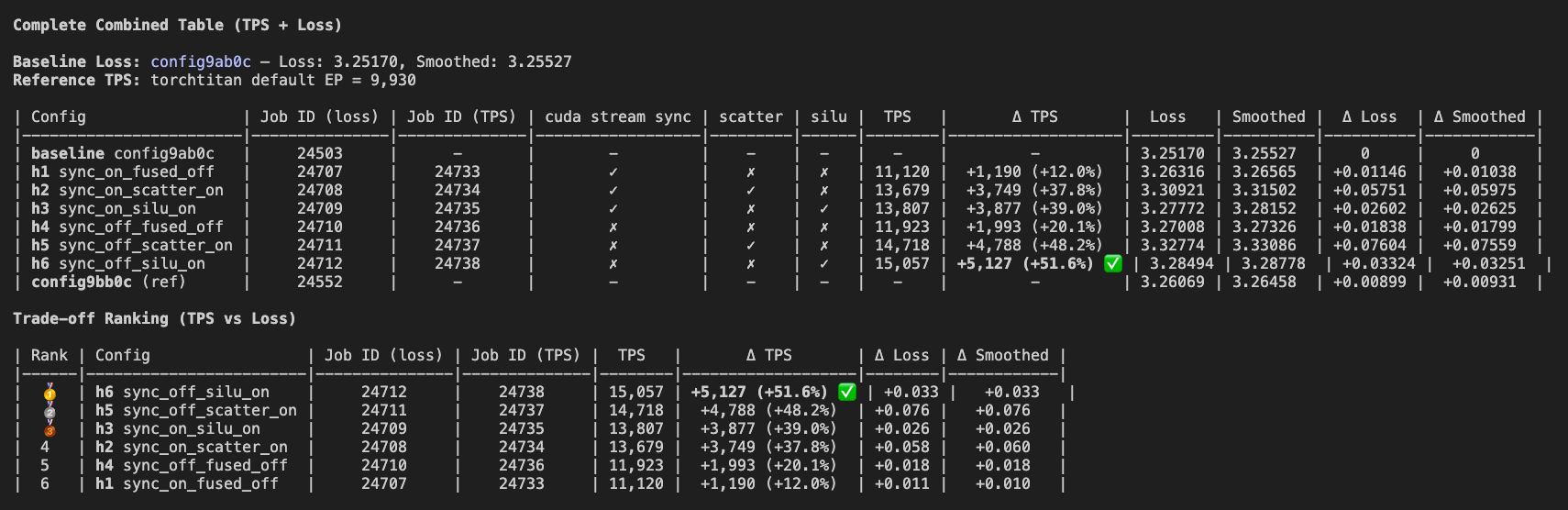
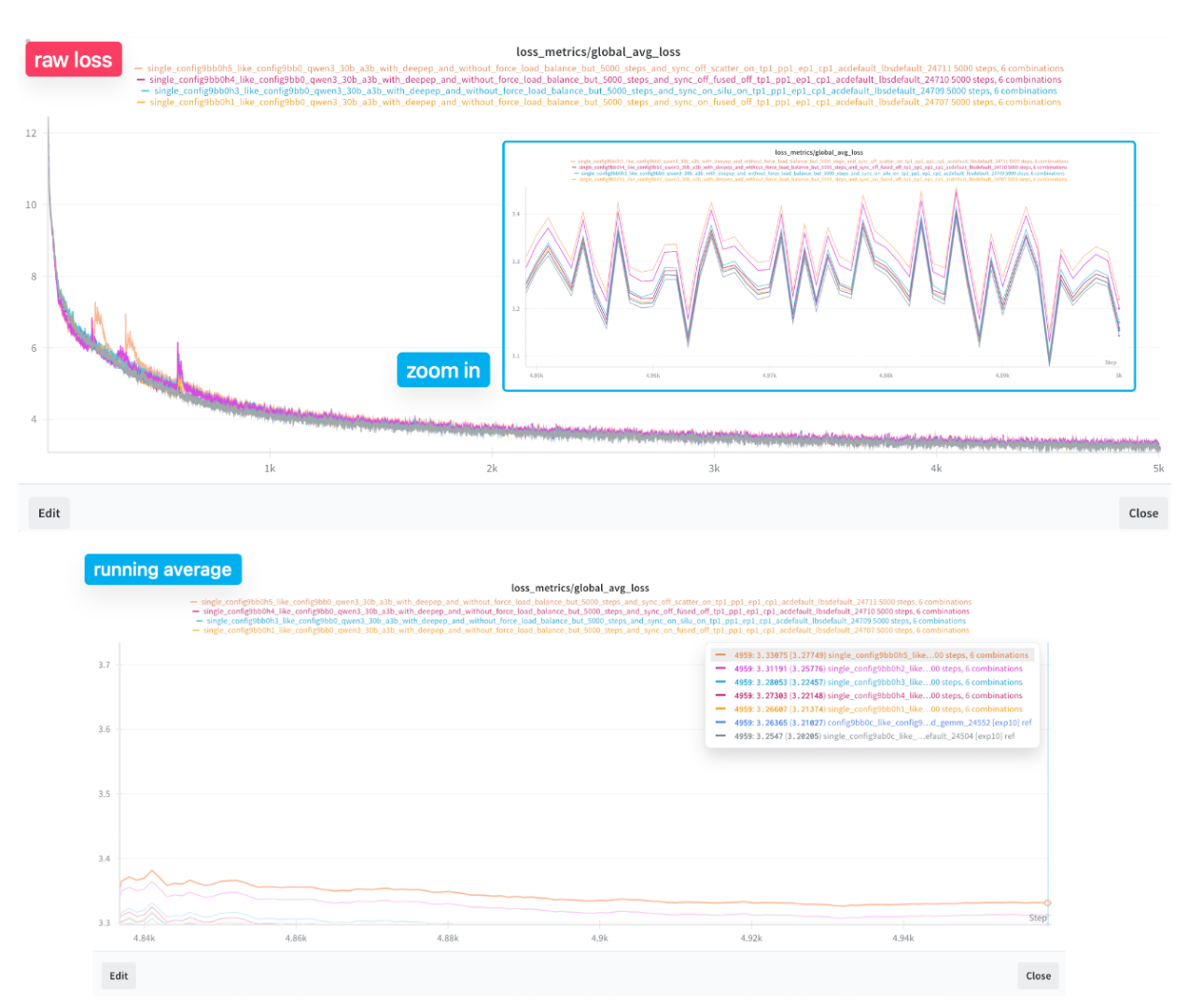
November 14 - Scaling Expert Parallelism Linearly
Fixed critical issues to achieve near-linear scaling of expert parallelism across nodes.
Problem 1: Intranode kernels scale poorly with expert parallelism
Intranode kernels (especially cached_notify_combine) scale poorly with expert parallelism (EP). I mitigated this by tuning the number of SMs (num_sms) allocated to DeepEP.
Using the Nsight report for EP=2 and EP=4, the top-15 slowest kernels show that the DeepEP intranode kernels dominate the GPU time. The worst is: deep_ep::intranode::cached_notify_combine(int)
EP=4 – Top 15 Kernels
void deep_ep::intranode::cached_notify_combine<(int)4> void **, int *, 54.306s ( 38.1%)
ncc!DevKernel_AllGather_RING_LL`ncc!DevKernelArgsStorage< unsigned lon 17.169s ( 12.1%)
void deep_ep::intranode::dispatch<(int)4, (int)768, (int)8192> int4 *, 9.107s ( 6.4%)
void deep_ep::intranode::combine<__nv_bfloat16, (int)4, (int)768, (int 8.539s ( 6.0%)
void at::native::indexFuncLargeIndex<c10::BFloat16, long, unsigned int 4.289s ( 3.0%)
void cutlass::device_kernel<at::cuda::detail::enable_3x_kernel_for_sm1 3.930s ( 2.8%)
void at::native::_scatter_gather_elementwise_kernel<(int)128, (int)8, 3.583s ( 2.5%)
cudnn_generated_fort_native_sdpa_sm100_flash_bprop_f16_knob_3i_128x128 2.811s ( 2.0%)
ncc!DevKernel_ReduceScatter_Sum_T32_RING_LL`ncc!DevKernelArgsStorage< 2.559s ( 1.8%)
void at::native::elementwise_kernel<(int)128, (int)4, void at::native: 2.504s ( 1.8%)
void at::native::<unnamed>::multi_tensor_apply_kernel<at::native::<unn 2.246s ( 1.6%)
void deep_ep::intranode::cached_notify_dispatch<(int)4> const int *, i 2.226s ( 1.6%)
void cutlass::device_kernel<at::cuda::detail::enable_3x_kernel_for_sm1 2.045s ( 1.4%)
void at::native::<unnamed>::vectorized_layer_norm_kernel<c10::BFloat16 1.943s ( 1.4%)
void cutlass::device_kernel<at::cuda::detail::enable_3x_kernel_for_sm1 1.940s ( 1.4%)EP=2 – Top 15 Kernels
ncc!DevKernel_AllGather_RING_LL`ncc!DevKernelArgsStorage< unsigned lon 31.187s ( 30.5%)
void deep_ep::intranode::cached_notify_combine<(int)2> void **, int *, 19.856s ( 19.4%)
ncc!DevKernel_ReduceScatter_Sum_T32_RING_LL`ncc!DevKernelArgsStorage< 6.529s ( 6.4%)
void deep_ep::intranode::combine<__nv_bfloat16, (int)2, (int)768, (int 5.060s ( 5.0%)
void deep_ep::intranode::dispatch<(int)2, (int)768, (int)8192> int4 *, 3.468s ( 3.4%)
cudnn_generated_fort_native_sdpa_sm100_flash_bprop_f16_knob_3i_128x128 2.406s ( 2.4%)
void at::native::elementwise_kernel<(int)128, (int)4, void at::native: 2.064s ( 2.0%)
void at::native::_scatter_gather_elementwise_kernel<(int)128, (int)8, 1.843s ( 1.8%)
void at::native::<unnamed>::multi_tensor_apply_kernel<at::native::<unn 1.776s ( 1.7%)
void at::native::indexFuncLargeIndex<c10::BFloat16, long, unsigned int 1.742s ( 1.7%)
void cutlass::device_kernel<at::cuda::detail::enable_3x_kernel_for_sm1 1.696s ( 1.7%)
void at::native::<unnamed>::vectorized_layer_norm_kernel<c10::BFloat16 1.681s ( 1.6%)
cudnn_generated_fort_native_sdpa_sm100_flash_fprop_f16_knob_7_128x128x 1.602s ( 1.6%)
void at::native::detail::chunk_cat_cuda_kernel<float, c10::BFloat16>::T 1.441s ( 1.4%)
void deep_ep::intranode::cached_notify_dispatch<(int)2> const int *, i 1.397s ( 1.4%)
EP = 4: cached_notify_combine = 54.306 s (≈ 38.1% of GPU time)
EP = 2: cached_notify_combine = 19.856 s (≈ 19.4% of GPU time)
Result: 2.73× slowdown in that kernel when doubling expert parallelism.
Other DeepEP intranode kernels also scale poorly:
dispatch<int4>: 9.107 s vs dispatch<int2>: 3.468 s → 2.63× slower
combine<int4>: 8.539 s vs combine<int2>: 5.060 s → 1.69× slower
At the system level: EP=4 is 42.7% slower than EP=2 (4624 vs 6599 tokens/sec).
From csrc/kernels/intranode.cu:613-628, the kernel is launched with 1 + num_channels blocks, each block processes all ranks, assigning one warp per rank, so each block does 2× more work instead of adding more parallelism.
This explains the ~2.7× slowdown in cached_notify_combine and the general degradation of DeepEP intranode kernels at higher EP.
After fixing Problem 2 (see below) to make num_sms tunable, I swept over multiple SM counts and found a significantly better configuration:
num_sms = 128 (up from 24)
Dispatch Config:
- turbo_deepep_num_cus = 128
- turbo_deepep_dispatch_tuned_config = (32, 1024, 8, 128)
- Performance: 122.32 μs, 496.28 GB/sCombine Config:
- turbo_deepep_combine_tuned_config = (16, 256, 8, 128)
- Performance: 127.43 μs, 476.36 GB/sPerformance Improvements
Comparison vs Current Baseline (num_sms=24):
- Dispatch: 56.3% faster (279.69 μs → 122.32 μs)
- Combine: 61.8% faster (333.95 μs → 127.43 μs)
- Bandwidth: 2.28x higher for dispatch (217.90 GB/s → 496.28 GB/s)
- Bandwidth: 2.61x higher for combine (182.49 GB/s → 476.36 GB/s)Comparison vs Worst (num_sms=8):
- Dispatch: 83.0% faster (721.57 μs → 122.32 μs)
- Combine: 84.0% faster (794.58 μs → 127.43 μs)Problem 2: Make num_sms tunable in DeepEP's benchmarking script
While trying to tune num_sms, I discovered that DeepEP's intranode benchmarking/tuning code implicitly assumes a single fixed num_sms. Any attempt to change it mid-run would assert.
From csrc/config.hpp:61:
const int num_channels = num_sms / 2; // KEY: derived from num_smsThis breaks when we vary num_sms:
• Initial run (baseline config): num_sms = 24 → num_channels = 24 / 2 = 12
• Cached matrix shape becomes [4, 12] for a 4-rank setup.
• Later run in the same process, trying to test: num_sms = 32 → expects num_channels = 32 / 2 = 16
• DeepEP checks the cached matrix via an assertion in deep_ep.cpp:403: cached_matrix->size(1) == num_channels
• But the matrix is still [4, 12], so: Expected: 16, Actual: 12
Assertion fails → the tuner crashes as soon as num_sms changes. Because the Buffer's cached routing metadata is intrinsically tied to num_sms, but the code treats it as if it were reusable across configurations.
To unblock tuning, I changed the intranode benchmarking flow to create a separate Buffer instance for each num_sms value in the sweep.
Results: Our current EP runs achieve about 57% of the theoretical limit, while DeepEP's baseline reaches about 34% of the theoretical limit on their hardware.
DeepEP's Reference Squeeze (H800)
- Theoretical: 450 GB/s
- Achieved: 153 GB/s
- Squeezed: 34.0% of hardware capabilityYour Squeeze (B200)
- Theoretical: 900 GB/s
- Achieved: 516.71 GB/s
- Squeezed: 57.4% of hardware capability